

来源:google AI blog
本文转载自:新智元 | 编辑:LRS
自动驾驶里视觉一直为人所诟病,特斯拉就是经常被拉出来批判的典型。谷歌最近开发了一个新模型,效果拔群,已被CVPR2021接收。
对于人来说,看一张平面照片能够想象到重建后的3D场景布局,能够根据2D图像中包含的有限信号来识别对象,确定实例大小并重建3D场景布局。
这个问题有一个术语叫做光学可逆问题inverse optics problem,它是指从视网膜图像到视网膜刺激源的模糊映射。
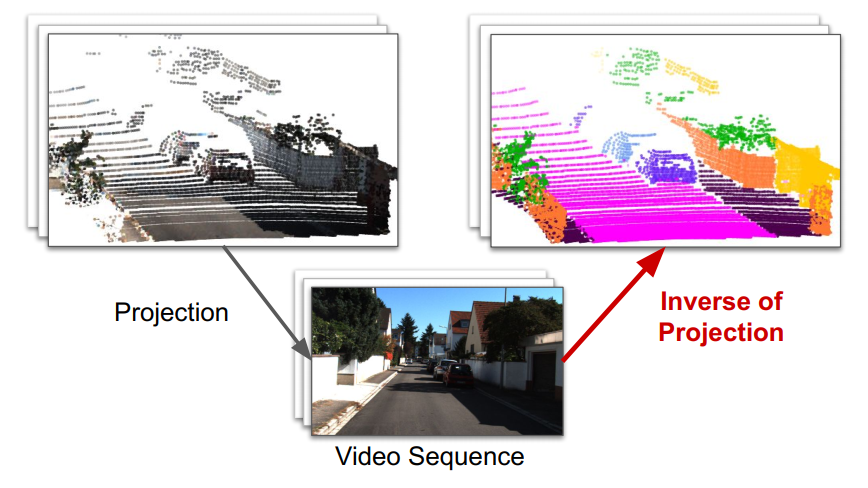
现实世界中的计算机视觉应用,例如自动驾驶就严重依赖这些功能来定位和识别3D对象,这需要AI模型来推断投影到2D图像的每个3D点的空间位置、语义类别和实例标签。
从图像重建3D世界的能力可以分解为两个独立的子任务:单目深度估计(从单个图像预测深度)和视频全景分割(实例分割和语义分割)。
研究人员通常对每个任务提出不同的模型,通过在多个任务之间共享计算的模型权重。在实际应用的时候,将这些任务与统一的计算机视觉模型一起处理可以简化部署提高效率。
基于这个研究背景,Google提出一个全新的模型ViP-DeepLab,通过深度感知视频全景分割来学习视觉感知,已被CVPR 2021接受,旨在同时解决单目深度估计和视频全景分割。
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
论文:https://arxiv.org/abs/2012.05258
数据集:https://github.com/joe-siyuan-qiao/ViP-DeepLab
论文中还提出了两个数据集,并提出了一种称为深度感知视频全景质量(DVPQ)的新评估指标,这个新指标可以同时评估深度估计和视频全景分割。
ViP-DeepLab是一个统一的模型,可以对图像平面上的每个像素联合执行视频全景分割和单目深度估计,并在子任务的几个学术数据集取得了sota结果。

ViP-DeepLab通过从两个连续的帧作为输入来执行其他预测,输出包括第一帧的深度估计,它为每个像素分配一个深度估计值。
此外,ViP-DeepLab还对出现在第一帧中的对象中心执行两个连续帧的中心回归,此过程称为中心偏移预测,它允许两个帧中的所有像素分组到出现在第一帧中的同一对象。如果未将新实例匹配到先前检测到的实例中,则会出现新实例。

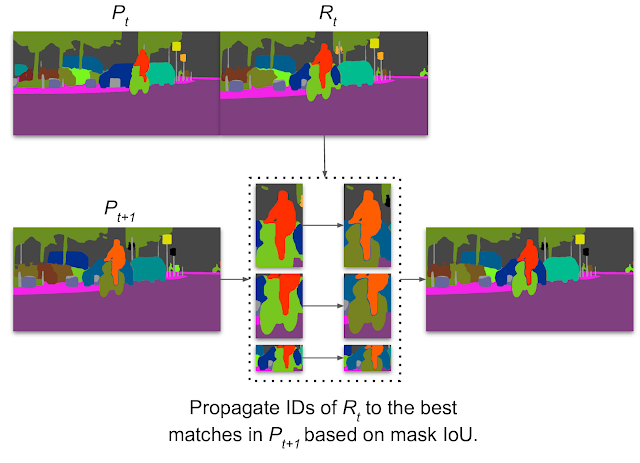
ViP-DeepLab的输出可以用于视频全景分割。连接两个连续的帧作为输入。语义分割输出将每个像素与其语义类别相关联,而实例分割输出则从与第一帧中的单个对象相关联的两个帧中识别像素,输入图像来自Cityscapes数据集。
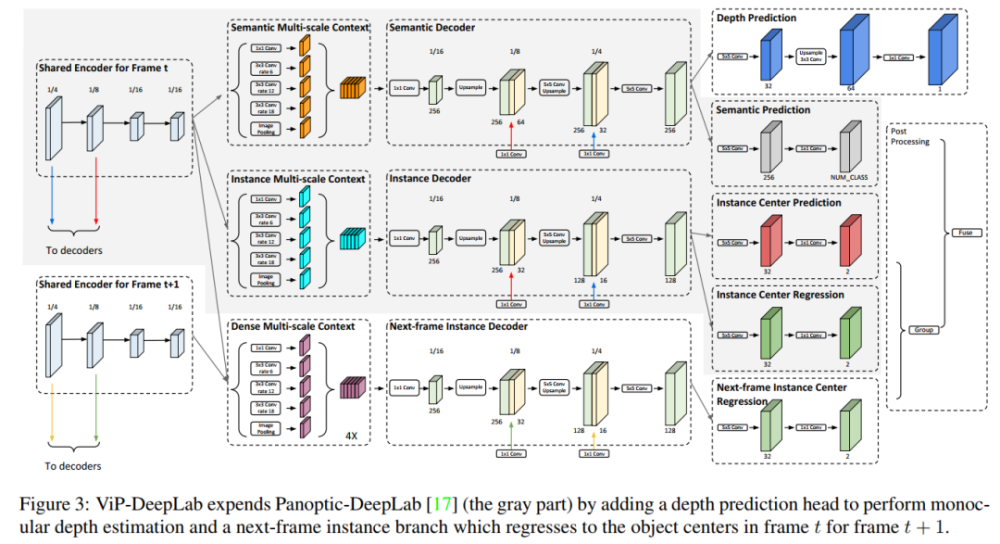
论文中在多个流行的基准数据集上测试了ViP-DeepLab,包括Cityscapes-VPS,KITTI深度预测和KITTI多对象跟踪和分段(MOTS)。
ViP-DeepLab都取得了SOTA的结果,在Cityscapes-VPS测试上,其视频全景质量(VPQ)大大优于以前的方法,达到了5.1%。
在KITTI深度预测基准上进行单眼深度估计的比较,对于深度估算指标,值越小,性能越好。尽管差异可能看起来很小,但在此基准上性能最高的方法通常在SILog中的间隙小于0.1。
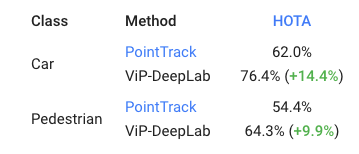
此外,VIP-DeepLab也在KITTI MOTS行人和汽车排名度量使用新的度量标准HOTA,都取得了显著提升。
最后,论文中还为新任务提供了两个新的数据集,即深度感知视频全景分割,并在其上测试了ViP-DeepLab,而这个模型的结果将成为社区进行比较的基准模型。
ViP-DeepLab具有简单的体系结构,可在视频全景分割,单目深度估计以及多对象跟踪和分割方面实现最先进的性能,这个模型也能帮助进一步研究对2D场景中的真实世界。
参考资料:
https://ai.googleblog.com/2021/04/holistic-video-scene-understanding-with.html













