
作者 | jinjunzhu 责编 | 张红月
出品 | 程序员jinjunzhu
Apache BookKeeper是一款企业级存储系统,最初由雅虎研究院研发,在2011年作为Apache ZooKeeper的子项目进行孵化,在2015年1月成为 Apache顶级项目。
起初,BookKeeper是一个预写日志(WAL)系统,经过几年的发展,BookKeeper的功能更加完善,比如为Hadoop分布式文件系统(HDFS)的NameNode提供高可用和多副本,为消息系统比Pulsar提供存储服务,为多个数据中心提供跨机器复制。
使用场景
BookKeeper最初的一个使用场景是为HDFS的NameNode保存edit log,如下图:
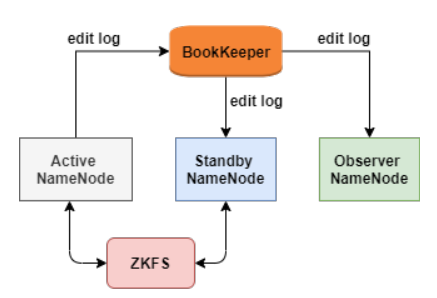
ZKFC是一个Zookeeper的客户端,主要用来监测和管理NameNode状态,每个NameNode机器上都会运行一个ZKFC,它的职责主要有三个:
健康检查
Zookeeper会话管理
选举,当集群中一个Active NameNode宕机,Zookeeper会自动选择一个节点作为新的Active NameNode。
BookKeeper记录NameNode的edit log(edit log存放文件系统的操作日志),NameNode的所有修改都会记录到BookKeeper。这样active NameNode宕机后,BookKeeper用保存的edit log去standby NameNode做回放,之后切换成active NameNode。
BookKeeper具有如下特性:
一致性:因为edit log保存的是HDFS的元数据,对一致性要求很高
低延迟:为了不丢数据,需要低延迟
高吞吐:为了支持更多的NameNode节点,需要高吞吐
节点对等
Bookie中保存的数据结构如下图:
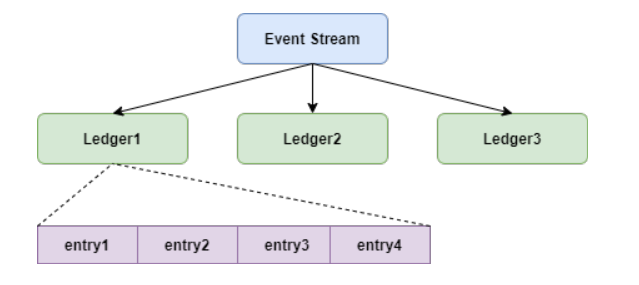
writer写数据时,把entry并发写入多个bookie节点的Ledger。这类似于文件系统写数据时首先会打开一个文件,如果文件不存在,则会创建文件元数据。
Ledger也就是Pulsar中的segment。
writer写数据时,首先会打开一个新Ledger,函数如下:
openLedger(组内节点数目、数据备份数目、等待刷盘节点数目)
比如(5,3,2)代表组内共有5个Bookie节点,写数据时需要写入3个节点,有2个节点返回成功代表写入成功。
这样写入的这3个节点数据完全一样,关系是对等的,不存在主从关系。
2.1 数据读写
BookKeeper数据读写如下图:
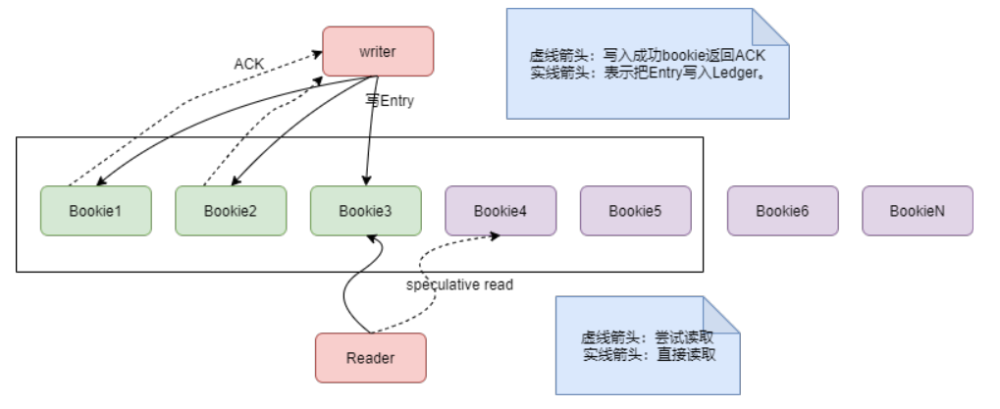
writer以roundrobin的方式写入bookie,比如在上图中,第一条数据写入Bookie1、Bookie2和Bookie3,第二条数据写入Bookie2、Bookie3、Bookie4,第三条数据写入Bookie3、Bookie4、Bookie5,第四条数据写入Bookie4、Bookie5和Bookie1。
在打开一个Ledger时,就传入了bookie数量,这样在写每个entry时,就用entry的id跟bookie数量取模,来确定写到哪几个bookie上。比如第3条消息跟5取模是3,就写到Bookie3、Bookie4和Bookie5。
这样以轮询的方式将Ledger数据写入各个bookie节点,每个bookie节点的数据是均衡的,每个bookie节点的磁盘带宽和网卡带宽都能得到充分利用。
2.2 读高可用
Reader在读取数据时,可以读取多份数据中的任意一份数据。BookKeeper会设置一个读超时时间,如果读取超时了,会给另外一个bookie节点(speculative read)发送读请求。
2.3 写高可用
如果某个bookie节点(比如bookie5)发生故障不能写入了,BookKeeper会做如下处理:
记录出错的entry id
对故障节点的数据进行封装
关闭当前的Ledger,重新打开一个新的Ledger,这个Ledger会重新选择bookie节点,1、2、3、4、6。
如果bookie5恢复,就不再提供写服务了,只提供读服务。
如果不能恢复,就把bookie5的数据,从其他节点的备份中恢复到新的节点上,这个过程需要根据Ledger id跟5取模来判断是否落到bookie5上,数据恢复过程并不影响Reader,因为其他两份数据可以继续提供服务。
I/O模型
BookKeeper的I/O模型如下图,这个图是单个bookie的数据流转:
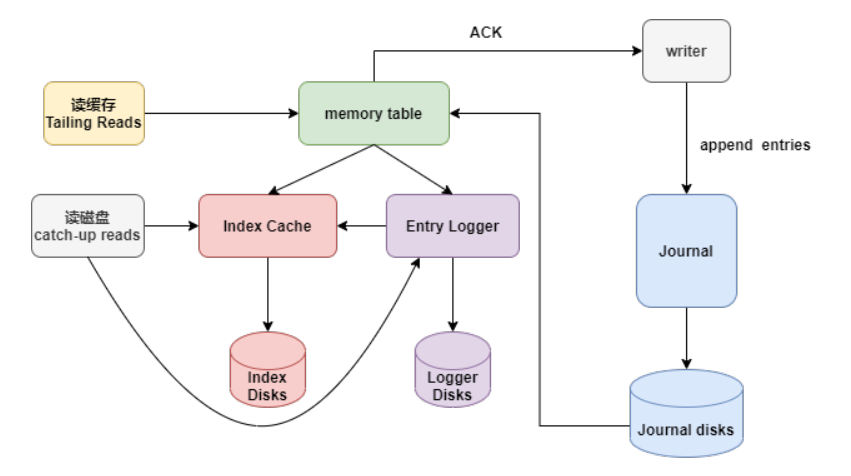
整个流程入下:
Writer写入的数据首先到达Journal,Journal将数据进行group后刷到到Journal盘,这个刷盘的数据顺序跟writer写入顺序一致。
Writer写入Journal Disk是实时刷盘。
Journal Disk的数据会写入memory table进行数据整理,把同一个topic的数据整理到一起。
把整理好的数据刷盘。Index Disk保存entry的index,对应entry在Logger Disks的offset。
3.1 读写分离
读取数据时,首先从Memory Cache中读取数据,如果数据不存在,才会去Index Disk和Logger Disk读取数据。而写数据是实时落盘到Journal Disk,这样实现了读写隔离。
3.2 强一致性
数据可以实时刷盘到Journal Disk,保证了数据的强一致性。
3.3 灵活SLA
对于写性能要求高的业务场景,可以单独加强Journal盘性能,而对于读性能要求高的场景,可以加强Ledger Disk和Index Disk的性能。
Pulsar中的使用
Pulsar的架构图如下:

每次Producer生成的消息实时落盘后,给Producer返回一个ACK。
Consumer消费消息后,还会修改Cusor中保存的offset,并且也会记录到BookKeeper。这样保证了Cursor的一致性。













