
作者 | 马超 责编 | 欧阳姝黎
出品 | CSDN博客
单核环境y也是0:其中一位非常细心的读者针对这个多核竞争造成问题的结论进行了验证,亲身在单核的环境ECS上实验,结果发现结果照样y=0。
后发先至:另外一位读者则给出了一个更奇怪的现象,两个变量中后执行的代码看起来却先被调用了。
加个if问题竟然解了:最后一个反馈留言最令人崩溃,在代码中随便加上个判断语句,不但解决了y=0的问题,性能还非常好。
难道这就是传说中的乱序执行?
先来看以下读者回复的代码:
在这部分内容中,两个变量x和y都是由原子操作Automic.Add来保证并发安全的,但是结果输出出来我们可以发现y竟然比x还大?而且每次运行的情况基本都是y更大,只是大多少有所区别。
看到这个输出结果,我第一反应感觉这是乱序执行的衍生现象,因为x和y的加1操作彼此是独立的,虽然编译器不会优化执行顺序,但是在CPU的执行层面有可能会对于前后无依赖的操作打乱顺序执行。这样一来就的确有可能出现后面的操作先执行的情况。
但是仔细一想这样的说法应该并不合理,如果是乱序执行的原因,那么上面这段代码的执行结果肯定不会每次结果都是y更大一些,每次执行都是y比x更大只能说明代码是按照一定顺序执行的,而且目前的CPU指令流水线的预测功能肯定还没有牛到能够完全知晓x与y的值不按照顺序提交是没有作何影响的地步。
仔细一看还是多并发竞争问题
再来看以下代码,
只要把fmt.println之前先把x和y的值拷贝出来到x1与y1,再打印x1与y1的值就基本没有这个误差了。
这也就是说,fmt.println在执行中间,go func中的子gorouine又被调度了。所以y比x的值大,本质又是一个多并发的竞争问题。而不是乱序执行的原因,只是这个问题在Go的开发模式下也是非常隐蔽。
崩溃了,单核怎么也是0
再说第二个令人崩溃的读者反馈,他在单核的云ECS尝试运行以下代码,
结果也是0。刚开始我觉得这个读者反馈有误,因此我也立刻在阿里云的X86集群与华为云的鲲鹏集群分别申请了一台单核ECS,不过结果令人崩溃,无论是ARM还是X86单核平台运行上述代表的结果也还是0,不过这还没完。
更崩溃了,随随便便加个if竟然杀疯了….
接下来是最令人崩溃的时刻,我们来看以下代码:
这段代码在没有作何锁或者互斥体的基础上竟然解决了y=0的问题,而且令人崩溃的是,这段代码的执行效率竟然还非常惊人,比之前Automic的方式至少快一个数量级,如果是这样的话那么这种代码方案就非常适合于不需要并发控制,并且定时需要结束的计算场景,假如我一个计算任务只能给1秒钟,能算得出来就算,算不出来就解下一题了,那么if的方案就非常适合了。
在解释if分支这个非主流的方案之前,我们再来看一下互斥体这种主流并发同步方案。
互斥体实现如下:
运行结果如下:
我们可以看到互斥、原子操作等方法最终运行结果基本都在一个数量级以内上下浮动,幅度不超过10%,对比之下if的方案实在是杀疯了,直接比上述这种安全的写法性能好出一个数量级!随便加入个if分支,竟然也能解决y=0,而且还是高效解决这到底是为什么?
关键时刻汇编令人心安,大神一语道破
在我的知识储备实在无法解释以上现象的时候,我只能将希望诉诸objdump,将gobuild生成的可执行文件来进行反编译,通过查看汇编语言代码来寻找问题解释的蛛丝马迹。不看不知道一看还真是有惊喜,加了if语句和加锁等方式一样全部会加上内存写屏障writeBarrier。具体如下:
未加if的汇编结果
加了if或者锁的汇编结果
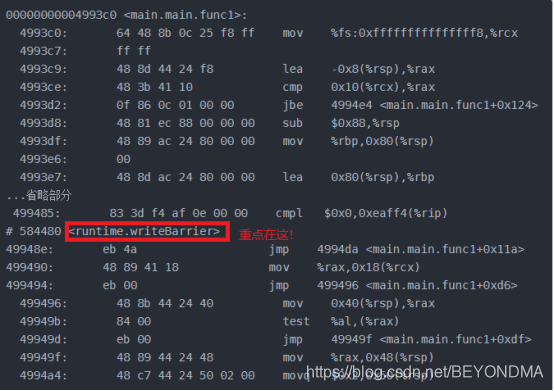
wirteBarrier有点类似于文件操作中flush的作用,会强制把数据由缓存同步到内存当中去,因此我前文中所说两个变量其中一个加锁,另一个结果也能不为0是因为他们在同一缓存行原因解释也不对,x和y并不是因为在同一个缓存行所以才被一起同步回内存的,而是由于wirteBarrier这个屏障所引入的。我们来看下面的代码。
他的运行结果是:
我造出来长度为10整形切片,缓存行一般只有64BYTE,那么这个切片上面的数据是不可能在同一缓存行上的,通过这段代码的执行结果可以看到所有切换的值全部被更新了,因此我们可以了解writeBarrier这个内存写屏障的功能是将之前所有的数据全部强制回写到内存当中。
另外针对最初代码中单核环境也能重现问题的情况,我请教了新版程序员中封面人物-操作系统大神熊大之后(图中右二为熊大)

我对于单核ECS中运行的结果也是y=0的结果有了一定的认识,由于ECS虚拟机运行的主体也是物理机,而物理机肯定不是单核的,因此不执行writeBarrier这个写屏障语句,数据也无法刷回内存,虽然程序运行在单核虚拟机上,而虚拟机并不会把汇编指令再做包装,这也就造成实际的执行与多核环境没有什么差别。
if为什么会被如此安排
实在中If不但实际达到了内存同步的效果,而且还效率更高,看起来非常适合这种没有强制同步需要的使用场景。不过我们不禁要问为什么编译器要在出现if语句时显式调用内存屏障。个人猜测原因有两个,
if判断使用真实值是隐含的前提:首先在进行判断时,使用缓存中的数据可能会带来显而易见的问题:因为在做判断时程序员一般是要求用目前变量的实际值而不是缓存值来进行的,这是一个隐含的前提,可能编译器在优化时考虑到了这一点。
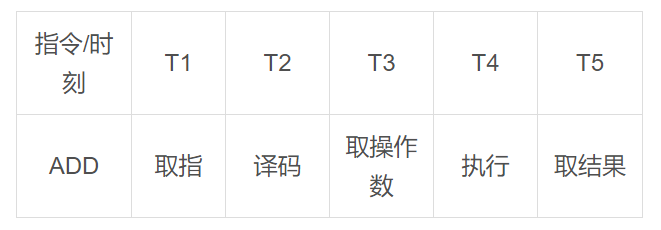
指令流水线的原因:我们知道CPU的每个动作都需要用晶体震荡而触发,以加法ADD指令为例,想完成这个执行指令需要取指、译码、取操作数、执行以及取操作结果等若干步骤,而每个步骤都需要一次晶体震荡才能推进,因此在流水线技术出现之前执行一条指令至少需要5到6次晶体震荡周期才能完成。如下图:
为了缩短指令执行的晶体震荡周期,芯片设计人员参考了工厂流水线机制的提出了指令流水线的想法,由于取指、译码这些模块其实在芯片内部都是独立的,完成可以在同一时刻并发执行,那么只要将多条指令的不同步骤放在同一时刻执行,比如指令1取指,指令2译码,指令3取操作数等等,就可以大幅提高CPU执行效率:
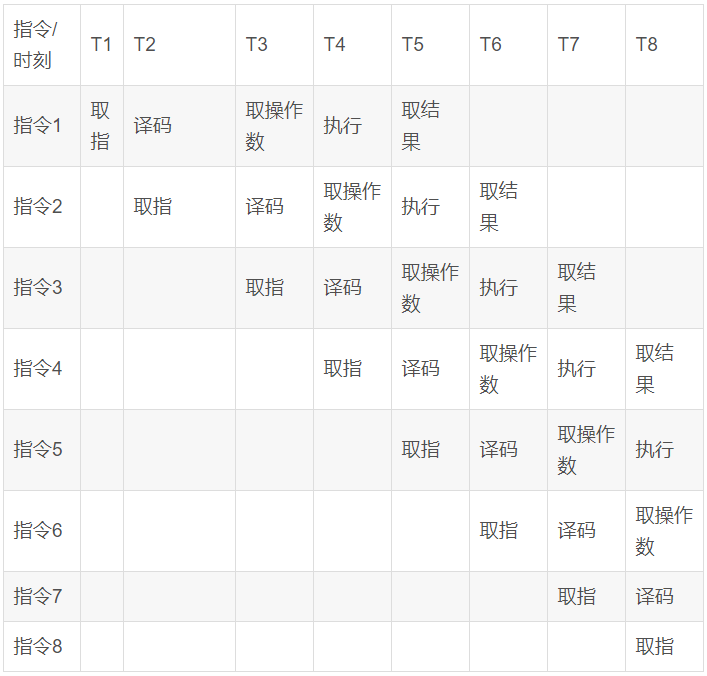
以上图流水线为例 ,在T5时刻之前指令流水线以每周期一条的速度不断建立,在T5时代以后每个震荡周期,都可以有一条指令取结果,平均每条指令就只需要一个震荡周期就可以完成。这种流水线设计也就大幅提升了CPU的运算速度。但是if分支会造成流水线的停顿,也就是说指令流水线系统无法确定在指令1执行时确定指令7的具体情况。那么在if时加上writeBarrier这种耗时操作其实也就可以理解了,反正if也造拖慢执行速度,那编译器也就不在乎在此时加上另外的耗时操作了。
Rust为什么令人羡慕
《一顿操作猛如虎,一看结果却是0》一文刊发后,也有很多大神人物回复说每种语言都有自己的生存方式,像Java的RxJava等高并发框架都可以做出很好的性能,笔者非常认同这一观点。
不过在看了一段时间的Rust后,我感觉Rust的优势是可以避免程序员犯很多错误,而这其中所谓的错误虽然看起来低级,但是如果他们被隐藏在千万行代码之中,那么排查起来真是相当费时费力,由于已经是所有权转移了,因此变量的使用不太会出现像Go一样的错误情况,这点我们在上一篇文章中已经有所论述了,而且我们来看以下代码:
可见Rust中连管道的多路并发的管理使用都要通过clone的方式来安全传递信息,个人根本想不到用Rust编程怎么能出现像上面例子中Go造成的Bug,因此Rust的学习曲线虽然陡峭,但是感觉Rust程序包往往只掌握原生的框架就可以做得很好了,而不像Python、Java除了原生语言知识以外,还需要学习熟练运用各种第三方的包。
马超,CSDN博客专家,阿里云MVP、华为云MVP,华为2020年技术社区开发者之星。













